Essential Components of a CI/CD Pipeline
24 Dec 2019Today I would like to talk about the topic of Continuous Integration and Continuous Delivery Pipelines. These have become a standard even for one-man teams for many reasons. Lets take a look at their anatomy, the truth is, you already have a pipeline if you develop software, even though it may be completely manual. As soon as we define CI/CD components, one can start to see them in their own processes, and also start to automate parts of it. I would like to talk in abstracted way, because this concept may be applied in many fields of software development. Even though one might start thinking about web application development by default when talking about CI/CD, this is not necessarily the case. CD/CD processes are applicable for any area of software development. Even though I have no real life experience with embedded development, I believe that with the help of virtualisation it is possible to implement a solid process for empowering developers.
Here is the basic process of Continuous Integration and Continuous Delivery.
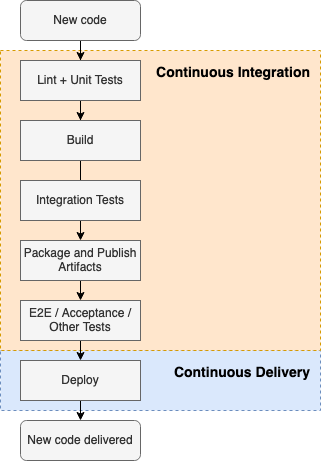
Development
As you can see, the Continuous Integration process starts with a commit of new code. It is preceded by the code development process itself, which is usually done directly on a developer workstation to have faster development cycle. As soon as the code is ready to be tested in a more extensive and controlled way, developer commits the code and starts a CI pipeline. It is important to note, that developer workstation is usually an uncontrolled environment and it varies greatly from one workstation to another. It also changes its state over time, meaning that new software gets installed in the environment, OS and software get updates. Other software which is not directly connected to the development process may also be running and taking system resources.
This is usually fine for the development process, as workstation owner usually has the control over his environment and (at least in most cases) knows which changes happened to it recently. As soon as we want to find out if the new changes in software will be performing in our production environment as expected, we need a controlled environment which, at least to some degree, resembles production environment.
Continuous Integration
Continuous Integration process is taking care of building code, running test suites and providing early feedback to developers. Common practice includes the following types of tests:
- Linting and Unit tests
- Integration tests
- End to End tests
It is quite often possible to run integration tests on developer machines, but when we are talking about Continuous Integration, we are talking about an automated way to monitor code for changes and providing feedback on these changes. Usually, a centralized version control system is acting as a single source of truth for code, therefore CI process must monitor it and provide feedback to all who is using this version control system.
In practice, CI system is usually monitoring some triggers in a VCS, for example somebody commits to a feature branch in git. CI system will notice that and start the pipeline. As soon as the pipeline is finished, the results are published in some way, a very common way is to publish brief results in a VCS with a link to CI system containing full logs.
Test suites need some environment to run on, therefore environment management is a big separate topic on its own. Ideally, End to End tests must run on environment which is equal to production, otherwise test results are valid only to some degree.
As soon as the code is tested and looks good, it can be packaged and delivered to QA or directly to the customers, depending on the established processes.
Continuous Delivery
Continuous Delivery process is responsible for delivering code to environments. It may take different forms, from developer logging in to machine and manually pulling new code, to a more sophisticated process, involving some deployment strategy, like for example blue green deployment, and even running DB migrations automatically.
Deployment process is based on many factors, like tolerance to downtime, system load, environment configuration and others. Ideally it must enable developers to effortlessly deploy, catch errors early and rollback fast in case some bug managed to slip through the tests and QA. CD process automation or at least documentation enables developers to keep and transfer the knowledge and increase the speed and quality of delivering value to the customers.
Summary
As you can see, CI/CD pipeline is basically documenting the delivery of application code to production (and possibly other) environments. Some parts of the pipeline can be manual, some parts can be automated. Ideally everything should be automated, because this allows continuous improvement of the CI/CD code itself and makes the codebase much easier to work for an external person. It takes some effort to set up the process, but benefits are huge. Most notably:
- Code delivery process becomes controlled and can be incrementally improved
- The barrier for contributing to the codebase lowers a lot allowing for faster developer onboarding
- Enforcing rules for running linting and tests improves code quality and lowers risk of regressions
- Standardisation of CI/CD process enables easier switching of development teams
- Automated CI/CD process increases the speed of delivering value to customers.